Current robotic planning methods often rely on predicting multi-frame images with full pixel details. While this fine-grained approach can serve as a generic world model, it introduces two significant challenges for downstream policy learning: substantial computational costs that hinder real-time deployment, and accumulated inaccuracies that can mislead action extraction. Planning with coarse-grained subgoals partially alleviates efficiency issues. However, their forward planning schemes can still result in off-task predictions due to accumulation errors, leading to misalignment with long-term goals. This raises a critical question: Can robotic planning be both efficient and accurate enough for real-time control in long-horizon, multi-stage tasks? To address this, we propose a Latent space Backward Planning scheme (LBP), which begins by grounding the task into final latent goals, followed by recursively predicting intermediate subgoals closer to the current state. The grounded final goal enables backward subgoal planning to always remain aware of task completion, facilitating on-task prediction along the entire planning horizon. The subgoal-conditioned policy incorporates a learnable token to summarize the subgoal sequences and determines how each subgoal guides action extraction>. Through extensive simulation and real-robot long-horizon experiments, we show that LBP outperforms existing fine-grained and forward planning methods, achieving SOTA performance.
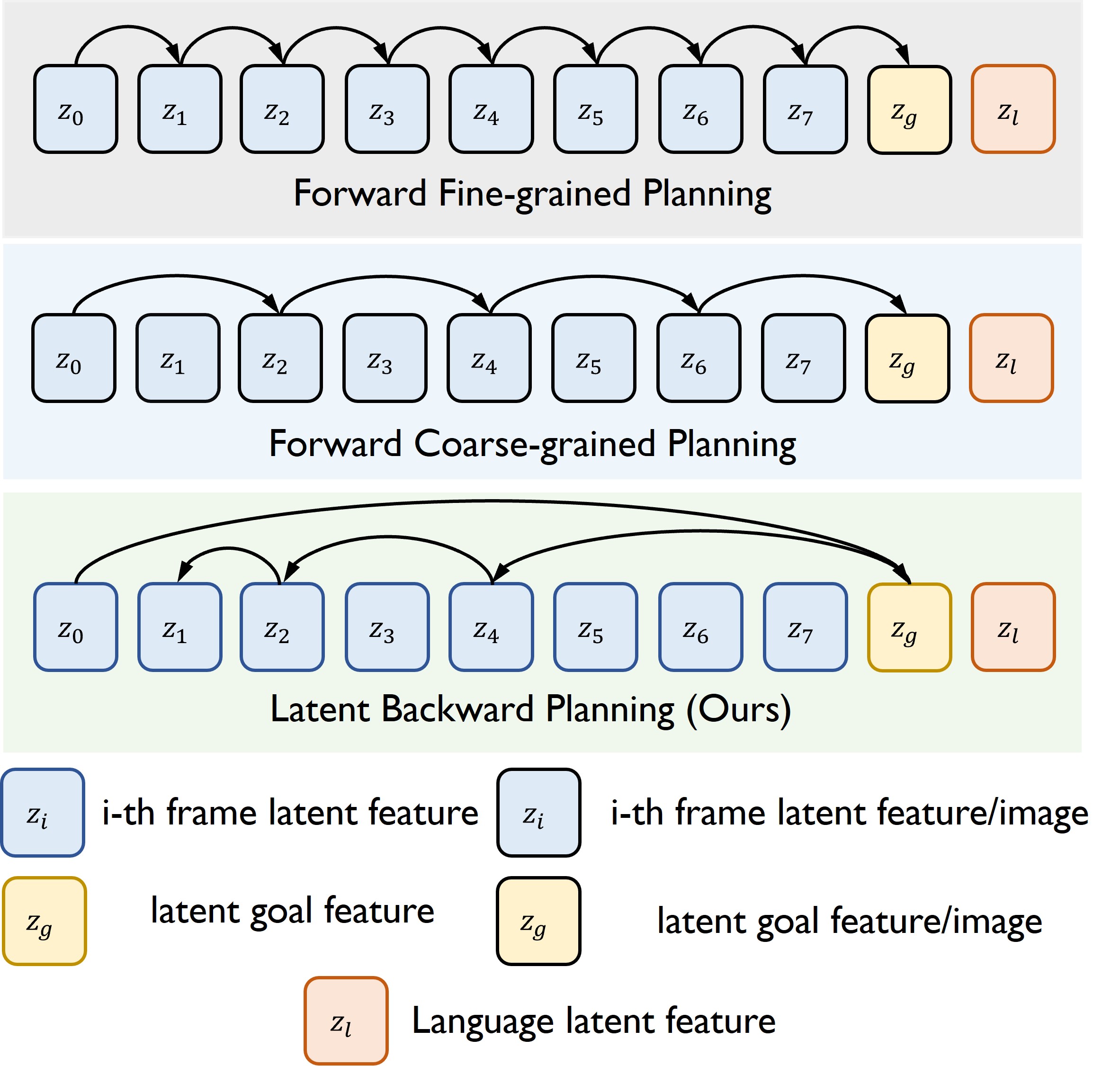
Figure 1. Illustration of latent space backward planning.
In the training phase, we learn a final goal predictor \( f_g \) with Eq.2, a unified subgoal predictor \( f_w \) with Eq.5, and a conditioned policy \( \pi \) with Eq.5. At each step \( t \) at test time, LBP processes the current observation \( I_t \) and language instruction \( l \) into latent state \( z_t \) and language feature \( \phi_l \), and then generates latent (sub)goal plans \( \{w_n, \dots, w_2, w_1, z_g\} \) by \( f_g \) and \( f_w \). Then we use the contexts \( c \), including predicted goal plans and language features \( \phi_l \), to condition the policy \( \pi(a_t \mid s_t, c) \) for action extraction.
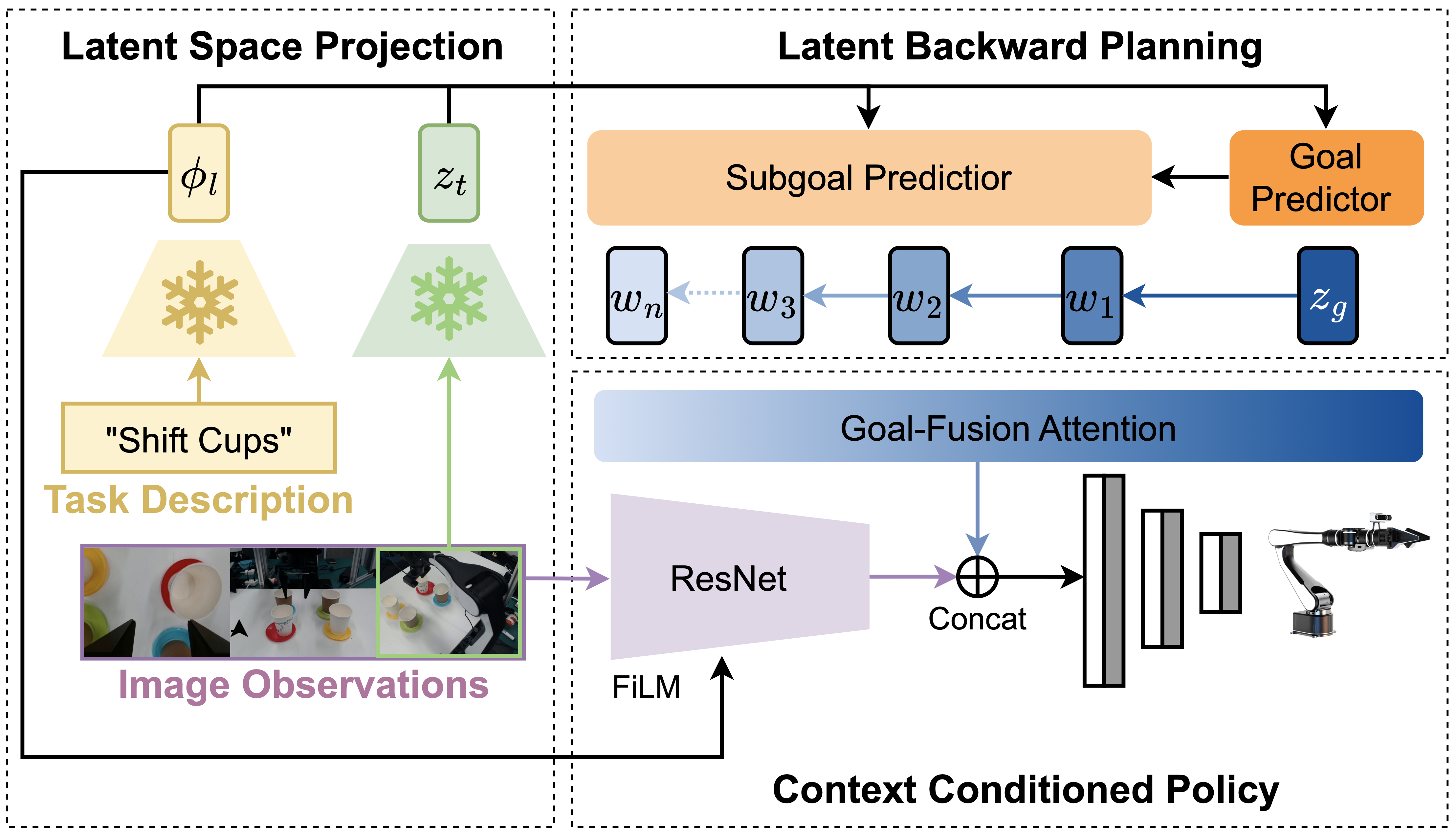
Figure 2. Overall framework architecture of LBP.
LIBERO-LONG consists of 10 distinct long-horizon robotic manipulation tasks that require diverse skills such as pick-ing up objects,
turning on a stove, and closing a microwave. These tasks involve multi-stage decision-making and span a variety of scenarios,
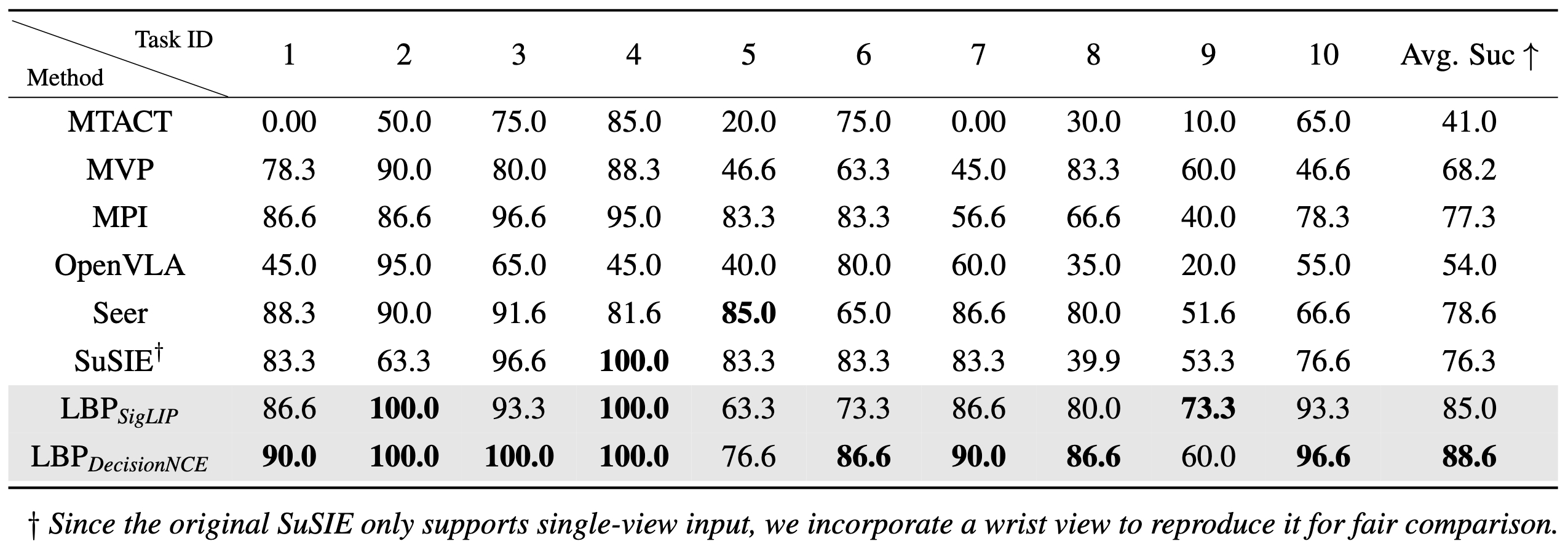
making them particularly challenging. Table 1 presents the quantitative comparison on the LIBERO-LONG benchmark.
LBP outperforms all baselines, achieving higher success rates across the majority of tasks.
Table 1. LIBERO-LONG results. For each task, we present the average performance of top-3 checkpoints. The metric ``Avg. Success'' measures the average success rate across 10 tasks. LBP outperforms baselines with higher Avg. Success and better results on most tasks. The best results are bolded.
To investigate the effectiveness of LBP in real world, we specifically design four long-horizon tasks: Stack 3 cups, Move cups, Stack 4 cups and Shift cups.
Each task is decomposed into multiple sequential stages, as shown in Figure 3, requiring the robot to perform fundamental pick-and-place operations.
These tasks establish a critical dependency where progress in subsequent stages is contingent on successful execution of preceding ones.
We assess task performance using a stage-based scoring system with discrete values {0, 25, 50, 75, 100} for each stage, where each score corresponds to the completion progress of the current stage.
A stage is assigned 100 only upon successful completion of the entire stage. In Figure 4, we present the quantitative comparison on the real-world tasks.
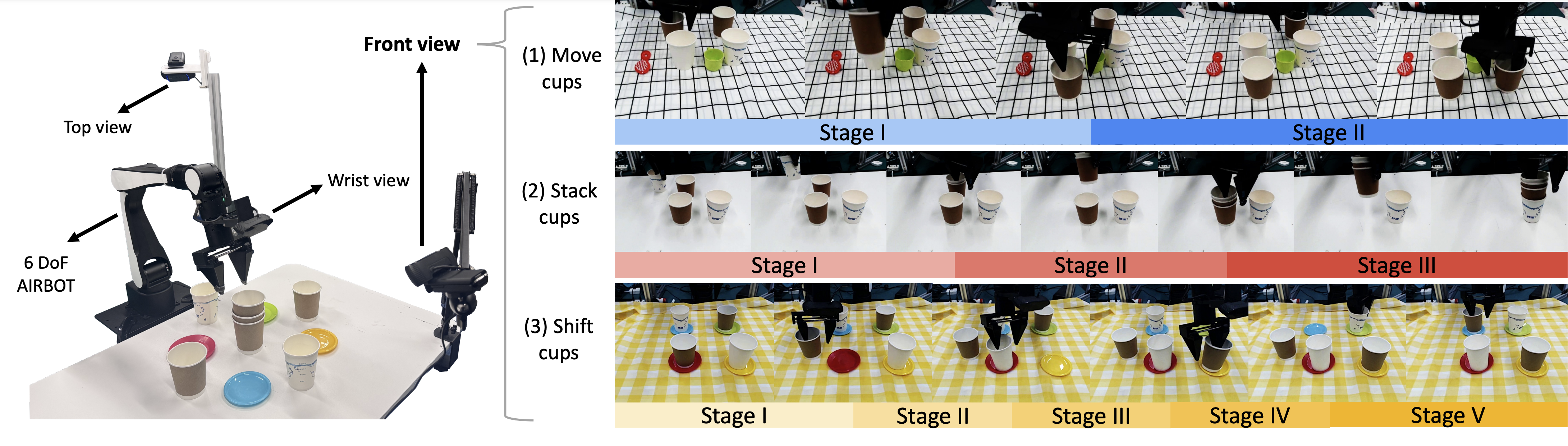
Figure 3. Left: the entire desktop environment setups of real-world experiments contains a 6 DoF AIRBOT arm and three Logitech cameras with different views; Right: (1) Move cups move both brown cups in front of the white ones; (2) Stack cups: stack all paper cups together; (3) Shift cups: shift all the paper cups to another plate, in a clockwise direction.
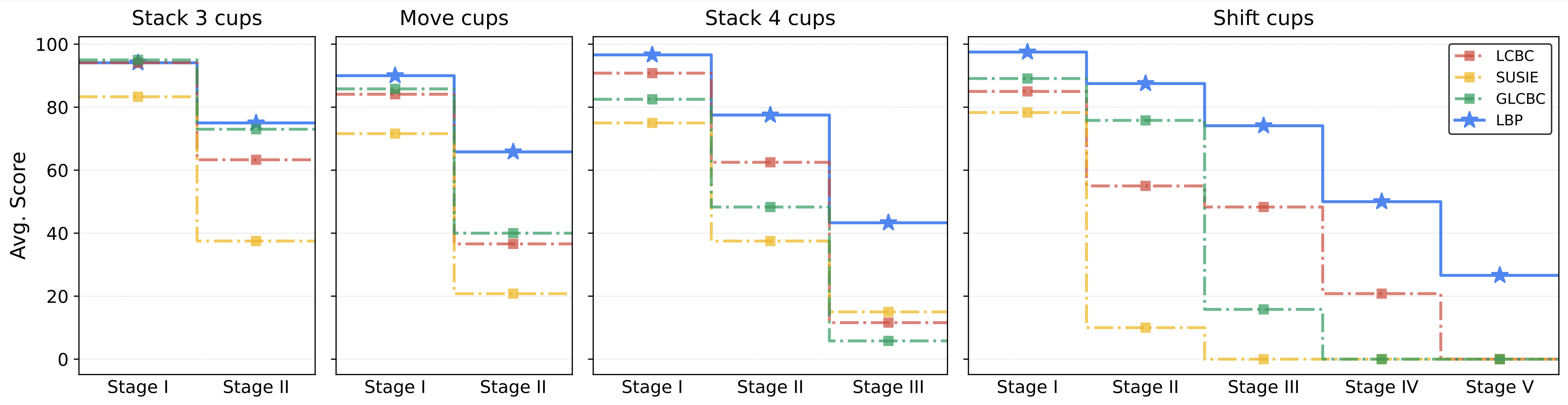
Figure 4. Real-world main results. We evaluate LCBC, GLCBC, SuSIE and LBP in aforementioned 4 tasks. For each task, we present the average performance of last-3 checkpoints. The metric "Avg. Score" measures the average score for each stage. We observe that while LBP slightly outperforms other strong baselines at the early stages, LBP wins by a fairly large margin at the final stages of all tasks. This shows LBP significantly excels in handling long-horizon tasks.
To evaluate the effectiveness of the backward planning approach, we compare it against a conventional forward planner and a parallel planner, both sharing the same hyperparameter setups to ensure a fair comparison. While the LBP model progressively predicts subgoals in a backward manner, the forward planner predicts the subgoal 10 steps into the future, and the parallel planner predicts all subgoals simultaneously. We randomly sample 3,000 data points representing the current state from our real-robot datasets and compute the mean squared error (MSE) between the predicted subgoals and their corresponding ground truths. The results are visualized below, with normalized task progress shown on the x-axis.
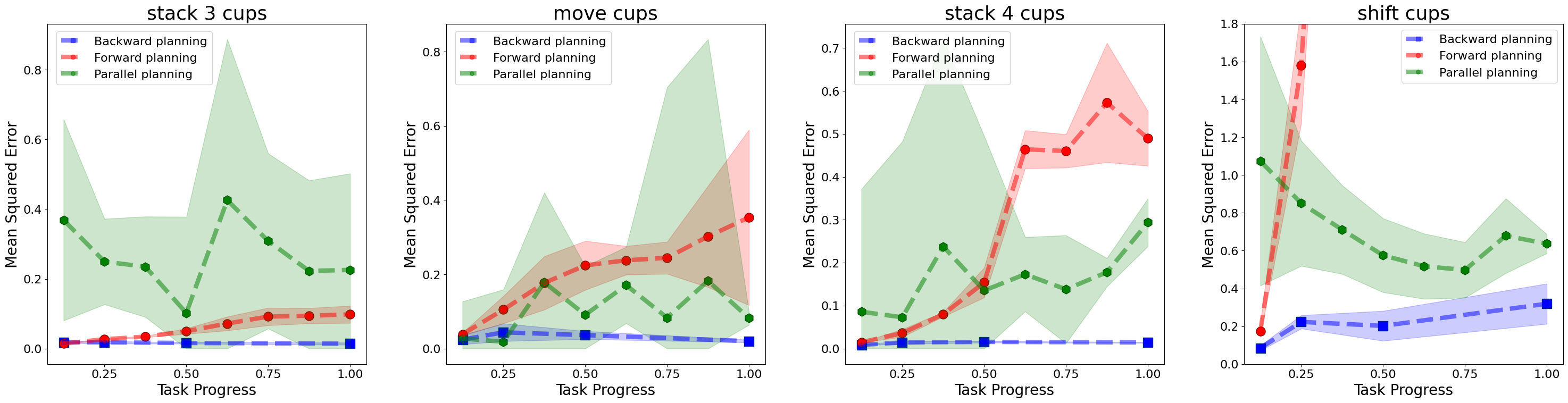
Figure 5. Mean Squared Errors (MSE) between predicted subgoals and corresponding ground truths in forward, parallel and backward planning (ours).
It can be observed that the compounding errors of forward planning increase rapidly across all tasks. In particular, for the most challenging task, Shift Cups, the prediction error becomes unacceptably large when forecasting distant subgoals. This issue is further exacerbated in approaches that attempt to predict continuous future image frames, where compounding errors can be even more severe. Although parallel planning avoids error accumulation by predicting all subgoals simultaneously, it suffers from consistently inaccurate predictions across the entire planning horizon. This limitation can be attributed to the difficulty of the training objective, which requires simultaneous supervision of all subgoals. Such an approach demands greater model capacity and incurs significantly higher computational costs. In contrast, our backward planning method maintains consistently low error across the entire planning horizon. These results highlight the advantages of our approach, which enables both efficient and accurate subgoal prediction.
@inproceedings{liu-niu2025lbp,
title={Efficient Robotic Policy Learning via Latent Space Backward Planning},
author={Dongxiu Liu and Haoyi Niu and Zhihao Wang and Jinliang Zheng and Yinan Zheng and Zhonghong Ou and Jianming Hu and Jianxiong Li and Xianyuan Zhan},
booktitle={International Conference on Machine Learning},
year={2025}
}